Selektor tagów
Selektory te widzieliśmy najczęściej podczas poprzednich lekcji. Użycie jest bardzo proste i za ich pomocą wybieramy konkretne tagi HTML, podając tylko ich nazwę, czyli np. <div>, <article> itp. Przykłady takiego zapisu widzimy w poniższym przykładzie.
/* Wszystkie tagi <span> zostaną otoczone zieloną ramką o szerokości 1px (px = piksele) */
span {
border: 1px solid green;
}
/* Wszystkie tagi <h2> będą miały czerwony tekst i wielkość czcionki równą 24px (px = piksele) */
h2 {
color: red;
font-size: 24px;
}Jak widać na powyższym przykładzie, definiując style dla konkretnego znacznika, definiujemy go dla każdego znacznika obecnego na stronie. Nie zawsze będziemy chcieli być aż tak ogólni. Takie tagi jak span czy p są dość często używane na całej stronie i nie koniecznie chcemy, aby wszystkie wyglądały tak samo. W takim przypadku możemy być nieco bardziej precyzyjni co do tego, które znaczniki chcemy stylizować, poprzez podanie ich częściowej lokalizacji w drzewie HTML. Podobnie w przypadku dublowania kodu CSS. Gdy mamy dwa elementy, na które chcemy nanieść ten sam styl, nie musimy pisać tego samego kodu dwa razy – wystarczy wymienić te elementy z użyciem przecinka ,.
Spójrzmy teraz na przykład. Śledząc znajdujący się tam kod oraz komentarze, możemy zobaczyć, w jaki sposób należy stworzyć selektory, aby te rozwiązały problemy opisane powyżej.
Hierarchia tagów HTML
Jak już wiemy z poprzednich lekcji, tagi HTML możemy zagnieżdżać w sobie:
<html>
<head>
<title>Hierarchia HTML</title>
</head>
<body>
<!-- Tag <section> jest zgnieżdżony wewnątrz tagu <body> -->
<section>
<!-- Tagi <h1> oraz <div> są zagnieżdżone wewnątrz tagu <section> -->
<h1>Nagłówek</h1>
<div>
<!-- Tag <p> jest zagnieżdżony wewnątrz tagu <div> -->
<p>Lorem ipsum text</p>
</div>
</section>
</body>
</html>W nomenklaturze HTML, tagi zagnieżdżone oraz tagi nadrzędne mają swoje własne nazwy, których będziemy używać podczas pracy z CSS. Trzy główne pojęcia, z którymi należy się zapoznać, to:
- parent (“rodzic”) – jest to nadrzędny tag, wewnątrz którego znajdują się inne tagi. W przykładzie powyżej tag
<body>jest “rodzicem” dla tagu<section>. Znacznik<section>z kolei jest “rodzicem” dla tagów<h1>oraz<div>. - child (“dziecko”) – “dziećmi” nazywamy znaczniki będące zagnieżdżone w innych znacznikach (tzn. znaczniki posiadające “rodzica”). Ponownie posługując się powyższym przykładem, tag
<section>jest “dzieckiem” tagu<body>natomiast tagi<h1>oraz<div>są dziećmi tagu<section> - sibling (“rodzeństwo”) – mianem rodzeństwa, określamy dwa znaczniki posiadające tego samego rodzica. W naszym przykładzie mamy tylko jeden taki przypadek, a więc tagi
<h1>oraz<div>. Są one dla siebie “rodzeństwem”.
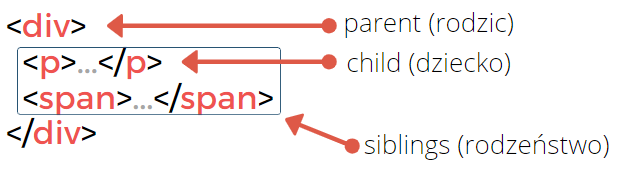
Przyjęcie nazewnictwa związanego z rodziną pozwala tutaj dość szybko zrozumieć zależności między kolejnymi zagnieżdżonymi znaczniki HTML. Pamiętajmy, że w drzewie HTML każde “dziecko” może mieć tylko “jednego” rodzica, tzn. że tag <section> z naszego przykładu jest rodzicem tylko dla tagów <h1> oraz <div>. Nie jest on rodzicem dla tagu <p>. Rodzicem tagu <p> jest znacznik <div>.
Kombinatory
Wykorzystując wiedzę na temat hierarchii znaczników HTML, możemy teraz tworzyć bardziej szczegółowe selektory. Użyjemy do tego tzw. “kombinatorów” (ang. Combinators), czyli dodatkowe oznaczenia używanego w selektorach. Najpopularniejsze z nich to:
- Child combinator (
tag1 > tag2) – przy użyciu tego kombinatora nasz selektor wybierze tylko te tagitag2, które są dziećmi tagutag1. - Adjacent sibling combinator (
tag1 + tag2) – kombinator używany do wybrania jedynie tych tagówtag2, które w drzewie DOM posiadają rodzeństwo będące znacznikiem tag1 i dodatkowo znaczniktag1występuje bezpośrednio przedtag2. - General sibling combinator (
tag1 ~ tag2) – podobnie jak w poprzednim punkcie wybieramy rodzeństwo, jednak w tym przypadkutag2nie musi wystąpić bezpośrednio po tagutag1.
Zobaczmy, jak to wszystko wygląda w praktyce: